

Resumen ejecutivo
Los LLM son brillantes, pero no omniscientes. Para responder con precisión usando conocimiento específico del negocio (políticas, catálogos, procedimientos) y reducir alucinaciones, la arquitectura RAG —Retrieval-Augmented Generation— se ha convertido en el estándar de facto.
En esta guía aprenderás qué es RAG, cuándo conviene frente a otras alternativas, cómo construir un agente RAG con herramientas open-source y qué buenas prácticas aplicar para que sea útil, seguro y medible en tu organización. Lo haremos con un enfoque práctico para PyMEs y equipos de negocio, conectando con marcos de confianza y personalización como pilares del marketing moderno.
📌 Lectura recomendada: Tipos de LLM y su uso definitivo para empresas
Qué es RAG y por qué es clave para datos internos
RAG combina dos elementos fundamentales: recuperación de información relevante desde una base de conocimiento (documentos propios, wikis, tickets, contratos) y generación con un LLM que “lee” esos fragmentos y redacta una respuesta contextualizada.
En términos simples: antes de contestar, el agente busca en tus fuentes y se apoya en ellas para responder. De este modo, mantiene la información actualizada, cita evidencias y acota el modelo a tu dominio, lo que disminuye las alucinaciones y mejora la rastreabilidad.
Este enfoque se alinea con una tendencia clave en el marketing digital impulsado por IA: las marcas que personalizan con datos propios y actúan con transparencia superan sus metas, porque ofrecen experiencias más relevantes y confiables. RAG es la pieza que permite a tu IA hablar con los datos reales del negocio, no con suposiciones.
RAG vs. Fine-tuning: ¿cuándo conviene cada uno?
RAG
Ideal si tienes mucha información cambiante (políticas, catálogos, precios, procedimientos) y quieres controlar las fuentes de cada respuesta. Escala rápido y cuesta menos que re-entrenar un modelo.
Fine-tuning
Útil si necesitas que el LLM adopte un estilo o proceso muy específico en tareas repetitivas (clasificación con etiquetas propias, por ejemplo). Requiere datos curados y ciclos de entrenamiento.
En la práctica empresarial, RAG es la primera elección: aporta precisión y frescura con inversión moderada. Si más adelante necesitas comportamientos específicos, puedes combinar RAG + fine-tuning. Este patrón híbrido es el que ya están siguiendo empresas que personalizan IA sobre bases internas.
📌 Relacionado: Chatbots vs. Agentes invisibles: ¿cuál necesita tu PyME?
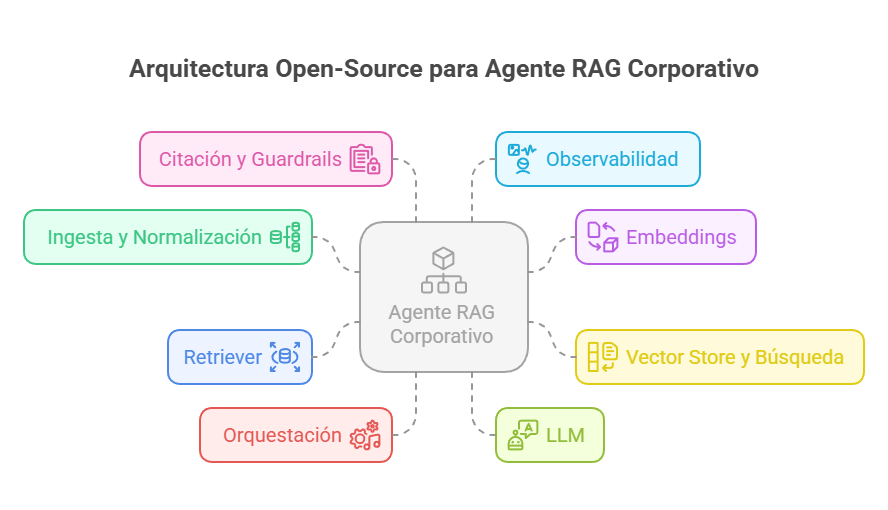
Arquitectura open-source para un agente RAG corporativo
Un agente RAG típico se construye con componentes bien establecidos del ecosistema abierto:
1. Ingesta y normalización
- Parseo de PDFs, DOCX, HTML, CSV
- Limpieza de caracteres, encabezados y tablas
- Segmentado (chunking) por semántica (encabezados, secciones) y tamaño (300–600 tokens) con metadatos (título, fecha, versión, etiqueta de confidencialidad)
2. Embeddings
- Conversión de fragmentos en vectores con modelos tipo sentence-transformers
3. Vector store y búsqueda
- Almacén vectorial para búsqueda ANN (Approximate Nearest Neighbors)
- Opciones open-source: Qdrant, Weaviate, Milvus
- Híbrido BM25 + vector para mezclar búsqueda léxica/semántica
4. Retriever
- Lógica de recuperación: k-NN, Maximal Marginal Relevance
- Filtros por metadatos (idioma, fecha, unidad de negocio)
5. Orquestación
- Frameworks como LangChain o Haystack para unir todo (ingesta, embeddings, retriever, formato del prompt, trazabilidad)
6. LLM
- Cerrado (OpenAI/Anthropic) u open-source (Llama/Mistral) según requisitos de datos y costo
7. Citación y guardrails
- El agente devuelve fuentes/URLs y aplica reglas (no responder si confianza < umbral)
8. Observabilidad
- Tracing y evaluación de respuestas (calidad, cobertura, latencia) para iterar
Paso a paso: cómo construir tu agente RAG de negocio
Paso 1: Define el caso de uso y el “momento de verdad”
Empieza donde el retorno sea tangible: soporte interno (RR.HH., TI, compras), atención a clientes con base documental (garantías, pólizas), o comercial (catálogos, fichas). Aquí conectas personalización con utilidad concreta para acelerar resultados.
Paso 2: Diseña el corpus canónico
- Identifica fuentes de verdad (drive, intranet, gestor documental)
- Homologa nombres, versiones y permisos
- Crucial: Sin orden documental, no hay RAG útil
Paso 3: Ingesta y chunking con metadatos
- Divide por secciones lógicas (H1/H2, tablas, bullets)
- Añade metadatos: área, país, idioma, vigencia, nivel de confidencialidad
- El chunking semántico mejora la precisión y evita ruido
Paso 4: Elige embeddings y vector store
- Si operas on-premise o datos sensibles: considera Qdrant o Milvus
- Si priorizas facilidad: Weaviate administrado
- Ajusta k, umbral de similitud y re-ranking por metadatos
Paso 5: Orquesta con LangChain o Haystack
Implementa un retriever híbrido (BM25 + vector) y prompt templates con secciones:
- Contexto: fragmentos recuperados
- Instrucciones: tono, formato, idioma
- Tarea: objetivo específico
- Criterios de respuesta: citar fuentes, no inventar
Paso 6: Guardrails y cumplimiento
- Regla “No sé”: si la confianza es baja o no hay contexto suficiente, el agente lo admite y sugiere la fuente
- Filtrado de PII y políticas (no exponer precios internos a clientes externos)
- Controles de acceso: el agente solo ve lo que el usuario puede ver
Paso 7: UX y embedding en procesos
- Integra el agente en canales naturales: web interna, sidebar en CRM, botón “preguntar a la base” en Helpdesk
- Para externos, usa live chat con handoff a humano si hay incertidumbre
Paso 8: Mide, aprende, itera
- Métricas: tasa de respuestas citadas, precisión subjetiva (calificaciones 1–5), tiempo ahorrado, resolución en primer contacto
- A/B testing de prompts, retrievers y re-rankers
- Ajusta chunking y metadatos según resultados
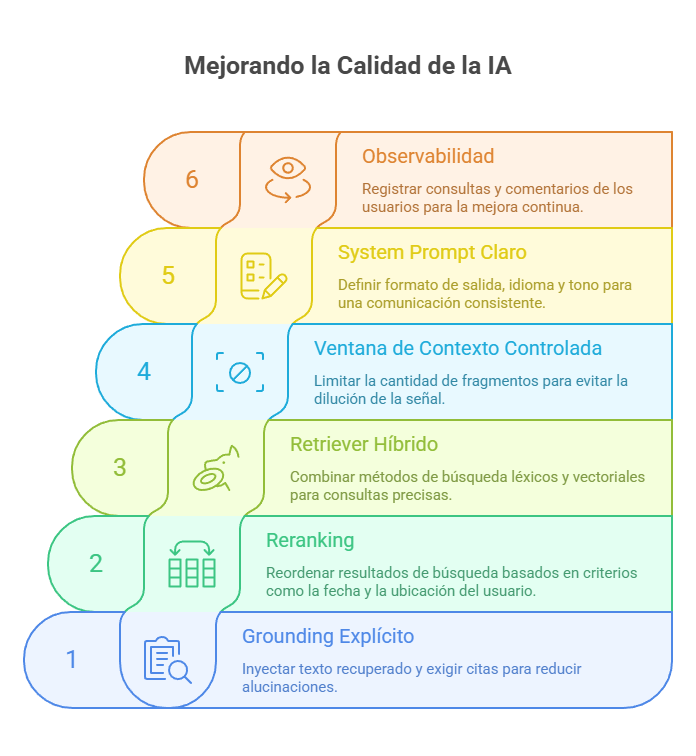
Buenas prácticas que elevan la calidad (y reducen alucinaciones)
Grounding explícito
Siempre inyecta texto recuperado y exige citas (ID de documento, enlace, fecha). Esto reduce alucinaciones y aumenta la confianza del usuario.
Reranking
Tras la búsqueda semántica, vuelve a ordenar resultados con criterios: reciente > antiguo, país del usuario, tipo de documento.
Retriever híbrido
Combina BM25 (léxico) + vectorial para preguntas con términos exactos (SKU, cláusulas, nombres propios).
Ventana de contexto controlada
Limita la cantidad de fragmentos; el exceso de texto diluye la señal.
System prompt con normas claras
Define formato de salida, idioma, tono, campos obligatorios (al final, lista de fuentes).
Observabilidad
Registra consultas, fragmentos usados, prompt final y evaluación del usuario para cerrar el ciclo de mejora.
Casos de uso para PyMEs
Asistente de políticas internas (RR.HH.)
Los empleados preguntan “¿Cómo solicito vacaciones?”; el agente responde con el párrafo vigente y cita la versión del documento.
Soporte técnico B2B
Respuestas sustentadas en manuales y runbooks. Si falta contexto, el agente adjunta enlaces al artículo de la base de conocimiento.
Ventas y pre-sales
Compara fichas técnicas y condiciones comerciales de dos líneas de producto citando ambos catálogos.
Compras
Extrae cláusulas de proveedores y sugiere riesgos; el humano valida y decide.
Stack abierto recomendado
- Ingesta: Procesadores de PDF/HTML/Markdown + normalización
- Embeddings: sentence-transformers (Hugging Face) o API según política de datos
- Vector DB: Qdrant (ligero y rápido), Weaviate o Milvus según escala
- Orquestación: LangChain (Python/JS) o Haystack para pipelines de producción
- LLM: Closed-source (calidad inmediata) u open-source (control y costo)
- Interfaz: Live chat (externo) y panel interno con trazabilidad
- Automatización: n8n para ingestiones programadas y webhooks de actualización
Riesgos comunes y cómo mitigarlos
Documentos obsoletos o contradictorios
Solución: Política de versiones y vencimientos, reranking por fecha, banner de “vigencia” en la respuesta.
Accesos laxos
Solución: El retriever respeta permisos; indexa solo lo que cada rol puede ver.
PII y confidencialidad
Solución: Filtros de PII y guardrails; enmascaramiento de datos en contexto.
Confianza ciega en la IA
Solución: Revisa métricas y habilita handoff a humano cuando la confianza sea baja.
Falta de adopción
Solución: Integra la IA en el flujo de trabajo (CRM, Helpdesk, intranet) con shortcuts útiles.
🔒 Descubre nuestro enfoque de seguridad y compliance en IA: Servicios LightStream en IA empresarial
Métricas de éxito que importan al negocio
- Tasa de respuestas citadas (≥ 1 fuente confiable por respuesta)
- Utilidad percibida (CSAT interno/externo)
- Resolución en primer contacto (FCR) y tiempo medio de respuesta
- Ahorro de horas operativas (antes vs. después)
- Cobertura de corpus (porcentaje de consultas respondidas con fuentes)
Estas métricas conectan directamente con resultados de marketing y experiencia: más relevancia, menos fricción y crecimiento sostenido.
📊 Si quieres medir el impacto de tu proyecto IA desde el día uno, revisa nuestro framework de métricas para automatización.
Implementación práctica (2–4 semanas por agente)
- Descubrimiento y priorización de casos (impacto vs. esfuerzo)
- Auditoría documental y diseño del corpus
- MVP de RAG con citación y guardrails
- Piloto con usuarios reales, iteración de prompts y retrievers
- Despliegue y capacitación, más playbook de mantenimiento
✅ Da el primer paso con un MVP de RAG: Contáctanos aquí
Conclusión: RAG como puente entre tu conocimiento y la IA
La promesa de la IA solo se cumple cuando responde con la verdad del negocio. RAG es ese puente: conecta tus datos con el poder de los LLM para ofrecer respuestas confiables, citables y actuales.
Si lo construyes con buen gobierno de datos, guardrails apropiados y medición continua, obtendrás un asistente experto que acelera a tu equipo y mejora la experiencia de clientes. La clave está en empezar por un caso de alto impacto y resultados medibles; el resto crecerá orgánicamente.